概述&&URLDNS
反序列化&&URLDNS
概述序列化与反序列化
Java序列化就是把Java对象转换为字节序列的过程(保存值和数据类型),而Java反序列化就是把字节序列恢复为Java对象的过程(恢复值和数据类型)
若要让某个对象支持序列化机制,则必须让其类是可序列化的:即该类必须实现如下两个接口之一:
Serializable 它里面没有任何方法,是一个标记接口
Externalizable 该接口有方法要实现,因此推荐第一个
为什么产生安全问题:
只要服务段反序列化数据,客户端传递类的readObject会自动执行,给予攻击者在服务器上运行代码的能力
可能的形式
入口类的readObject,直接调用危险方法(private 定义 readObject方法)
person 中定义代码
1
2
3
4private void readObject(ObjectInputStream ois) throws IOException, ClassNotFoundException {
ois.defaultReadObject();
Runtime.getRuntime().exec("calc");
}序列化
1
2
3
4
5
6
7
8
9
10
11public class SerializableTest {
public static void serialize(Object o) throws IOException {
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("ser.bin"));
oos.writeObject(o);
}
public static void main(String[] args) throws IOException {
Person person = new Person("xiao",18,01);
serialize(person);
}
}反序列化
1
2
3
4
5
6
7
8
9
10
11
12
13public class UserializableTest {
public static Object unserialize() throws IOException, ClassNotFoundException {
ObjectInputStream oos=new ObjectInputStream(new FileInputStream("ser.bin"));
Object ob=oos.readObject();
return ob;
}
public static void main(String[] args) throws IOException, ClassNotFoundException {
Person person= (Person)unserialize();
System.out.println(person);
}
}这里为什么Person中(有点类比重写的)这个readObject,方法必须是private属性的?还有为什么能在执行反序列化代码后能调用它,并执行它的代码呢??
(在序列化(反序列化)的时候,ObjectOutputStream(ObjectInputStream)会寻找目标类中的私有的writeObject(readObject)方法,赋值给变量writeObjectMethod(readObjectMethod)。)
重写
readObject()方法,并不是说重写父类中的方法,而是我们自定义了一个private修饰的readObject()方法,在反序列化的过程中检测到我们程序中存在private修饰的readObject()方法,就会去调用我们自定义的readObject()方法总结:如果目标类中没有定义私有的writeObject或readObject方法,那么序列化和反序列化的时候将调用默认的方法来根据目标类中的属性来进行序列化和反序列化,而如果目标类中定义了私有的writeObject或readObject方法,那么序列化和反序列化的时候将调用目标类中指定的writeObject或readObject方法来实现。
入口类参数中包含可控类,该类有危险方法,readObject时调用套用的第二层类
入口类参数中包含可控类,该类又调用其他又危险方法的类,readObject时调用
构造函数/静态代码块等类加载时隐式执行
共同条件 继承Serializable
入口类 source(重写readObject 参数类型宽泛 最好jdk自带)
(直接在类里面向上面的1.那样直接写不太现实,在类里面套一个类并且最好还是Object类的)在readObject中调用一个常见的函数(每一个对象都会调用的比如toString,hashcode)还是jdk自带的。hashMap就是一个符合条件的
URLDNS
入口类的条件
HashMap能够作为入口类的条件:
HashMap 实现类 implements Map, Serializable
接受的类型也比较多:因为需要接受键和值
重写readObject: 它要保证键的唯一性,当键是对象时需要重新写readOject方法来计算唯一性
readObject 最后实现URL发送dns请求
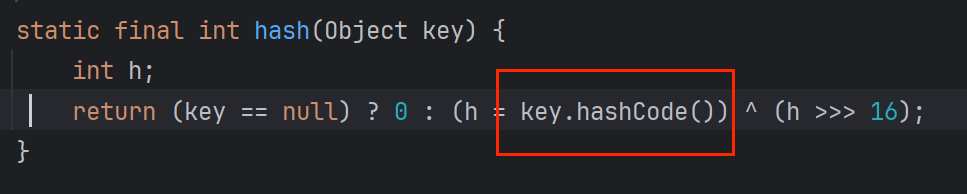
第一部分:入口类HashMap的readObject调用入口类HashMap的hash方法计算key的hashCode ,再调 key 的hashCode(调了两下,一下调到自己的hash,一下调到 key的hashCode),而key是我们传入的URL对象,最后就跳转成了调用URL的hashCode
HashMap readObject—>HashMap hash—-> key hashCode(即URL 的hashCode)
第二部分:URL的hashCode在计算时会调用getHostAddress来解析域名发送dns
URL.hashCode()—>URLStreamHander.hashCode()—>URL.getHostAddress()—>InetAddress->getByName()
具体过程
从入口类HashMap的readObject出发
第一下:看最后面 调HashMap的hash方法
1 | |
进入刚刚的调用 来到第二下:调key的hashCode方法
1 | |
下面这一部分就是URL的了
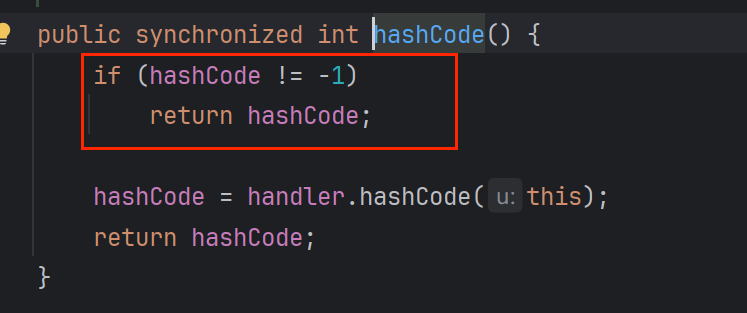
进入URL的hashCode后 有一个判断
如果hashCode不是-1 就会初始化变为-1并返回,如果是初始化的-1的话,才会执行下面的
就 继续 跳转到URLStreamHandler 的hashCode
1 | |
之后调getHostAddress 函数,就能发送dns请求了
———
URLDNS真正构造
按上面来讲是 反序列化时会自动调用入口类的 private readOject 然后进入上述流程完成发送请求的,但有个插曲,在写入url时HashMap的put方法 就已经导致在这时发送请求了
(因为put为了确保键的唯一,它就会计算key的hash先调用了HashMap的hash 和key的hashCode,hashCode就发生了变化)

put 的坏处:
我们误以为是序列化时就发送DNS请求
put改变了hashCode,所以在反序列化的时候hashCode不是-1,直接返回初始化-1不会执行下面的代码,不会发送请求了
总结思路:
- 入口类hashMap 创建对象
- 在put前用反射设置hashCode为非-1,防止put调用key的hashCode发送dns请求
- put方法丢进去url作为key值
- 反射设置回来url的hashCode为-1,再序列化对象,这样序列化就不会触发put的那一串发送请求,反序列化的时候就能(调用HashCode的private readObject,调啊调调到URL的hashCode了)发送dns请求了
1 | |
最后总结
需要两半部分,A部分作为入口类,反序列化的时候会自动调用A的参数o的f方法(即入口类hashMap,反序列化的时候会自动调用readObject方法,进而执行key的hashCode方法)
B部分需要有好的方法( 即能发起dns请求的URL类的hashCode方法)
B类里面的方法可以达到目的但(由于readObject 后面不能继续利用了)不能直接作为入口类
B类是后半部分的成品,A类是前半部分的成品
两部分结合(即同名函数替换): 条件:B类就 要与 能直接调的A类的方法中的参数类型 是相同类型(相同或是父子类),再调A中方法传进B类的参数—>相当于调B中的方法
注意点:在传入B类参数即(URL)时用到put方法也会触发发送dns请求的那一串,在put前反射修改hashCode值为非-1,put后修改为-1,最后序列化,在反序列化的时候发送请求